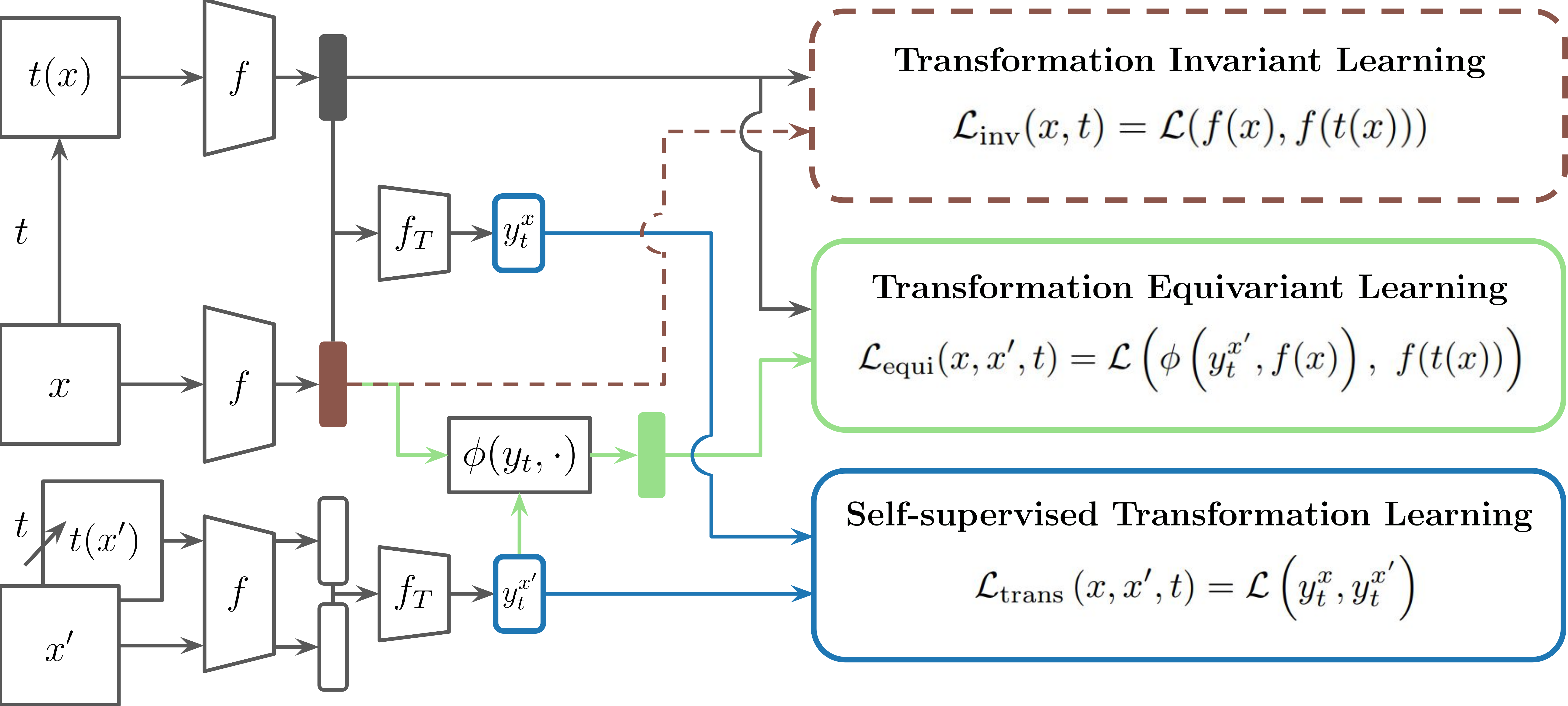
STL (Self-supervised Transformation Learning) is a novel equivariant representation learning method that eliminates the need for explicit transformation labels. Instead of relying on predefined transformation labels, STL learns transformation representations directly from image pairs, allowing for more structured and generalizable representations.
- No Labels Required: Learns transformation representations without explicit transformation labels.
- Scalable & Efficient: Same batch complexity as contrastive learning methods.
- Handles Complex Transformations: Supports AugMix and other challenging transformations.
- State-of-the-Art Performance: Outperforms existing methods across multiple benchmarks.
How It Works
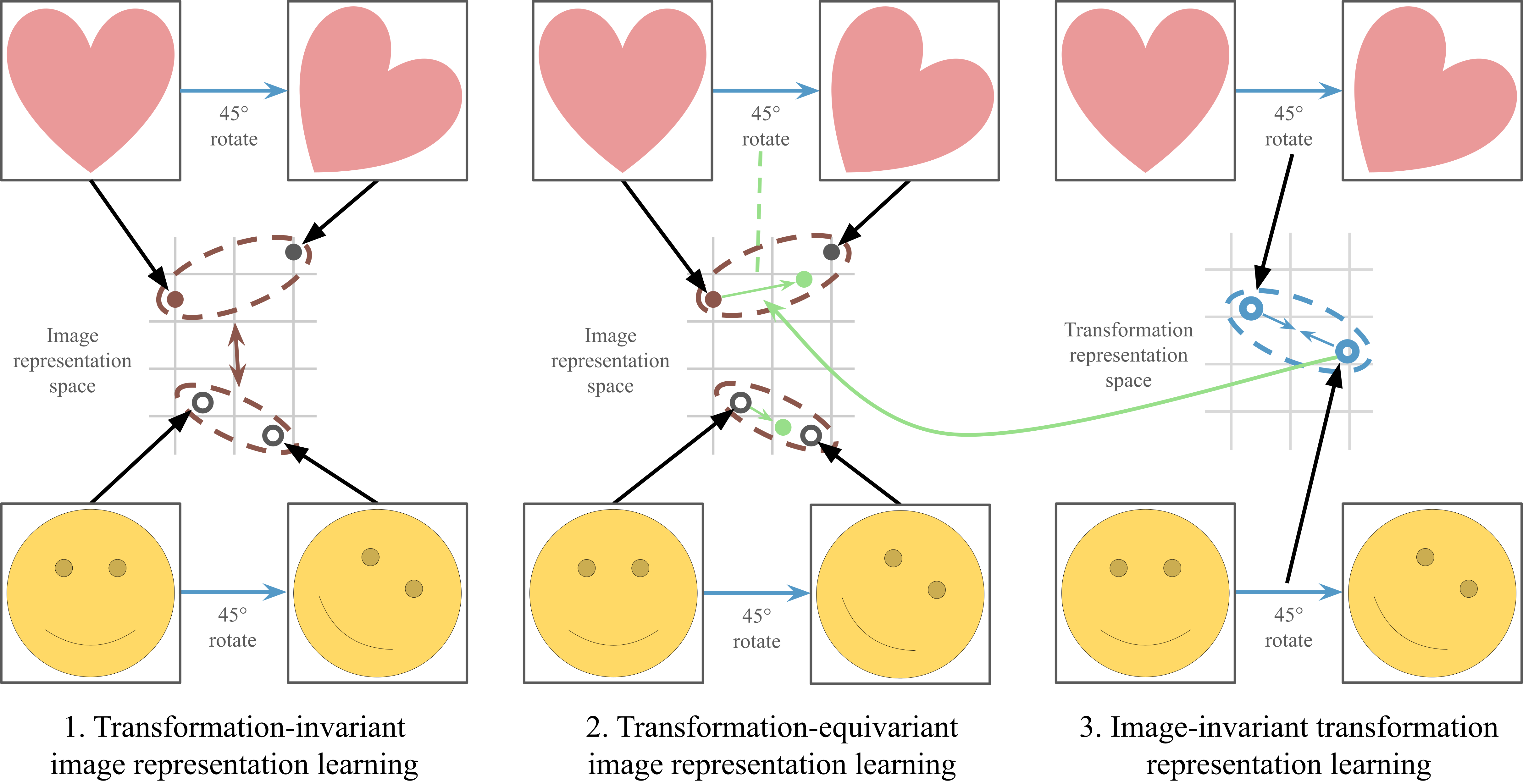
STL operates through three key learning processes:
1. Transformation-Invariant Image Representation Learning
- Ensures that the representation of different images remains distinct while maintaining invariance to transformations.
- This helps in learning stable and meaningful image features.
2. Transformation-Equivariant Representation Learning
- STL trains representations so that transformed images undergo the correct equivariant transformation.
- This makes models more transformation-sensitive, capturing and representing transformations effectively.
3. Image-Invariant Transformation Representation Learning
- STL learns transformation representations that remain consistent across different images.
- This improves generalization and enables robust handling of complex transformations like AugMix.
Results
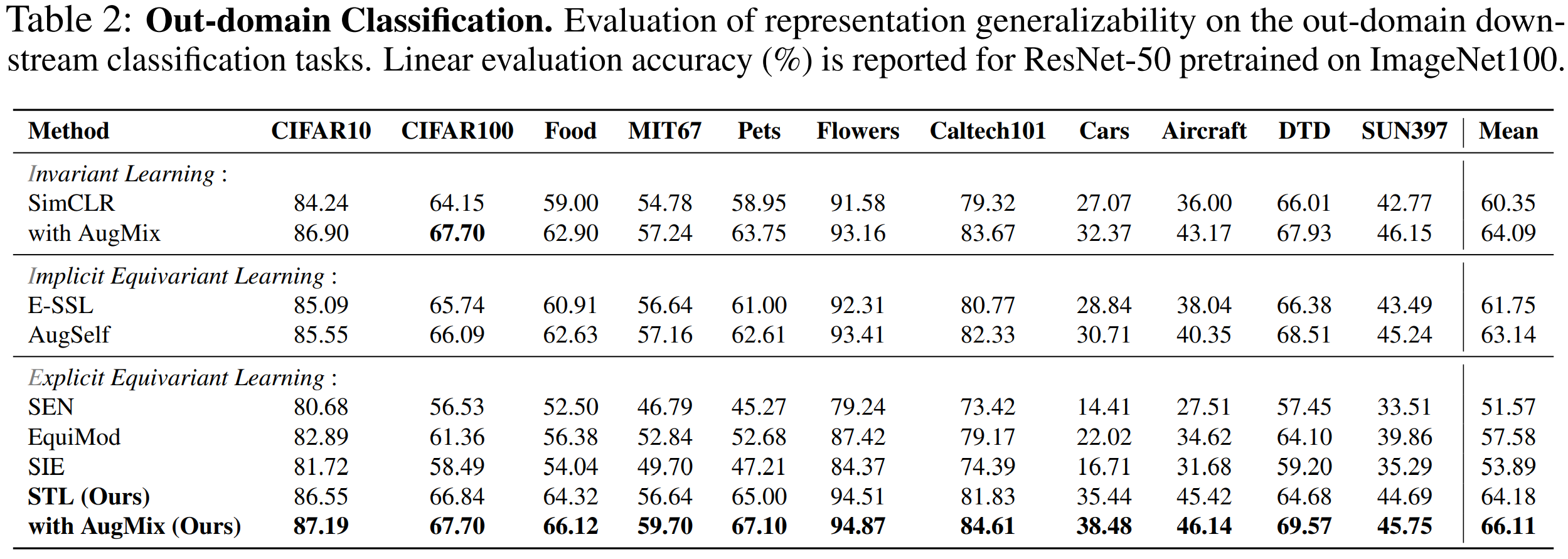
How generalized the learned representation is
STL significantly improves representation generalization across diverse datasets. By capturing transformation-aware features, STL outperforms existing methods in out-of-domain classification, achieving higher accuracy on ImageNet100-pretrained ResNet-50 evaluations.
- STL with AugMix achieves the highest mean accuracy across 11 benchmarks.
- Excels in recognizing fine-grained features that invariant learning struggles with.
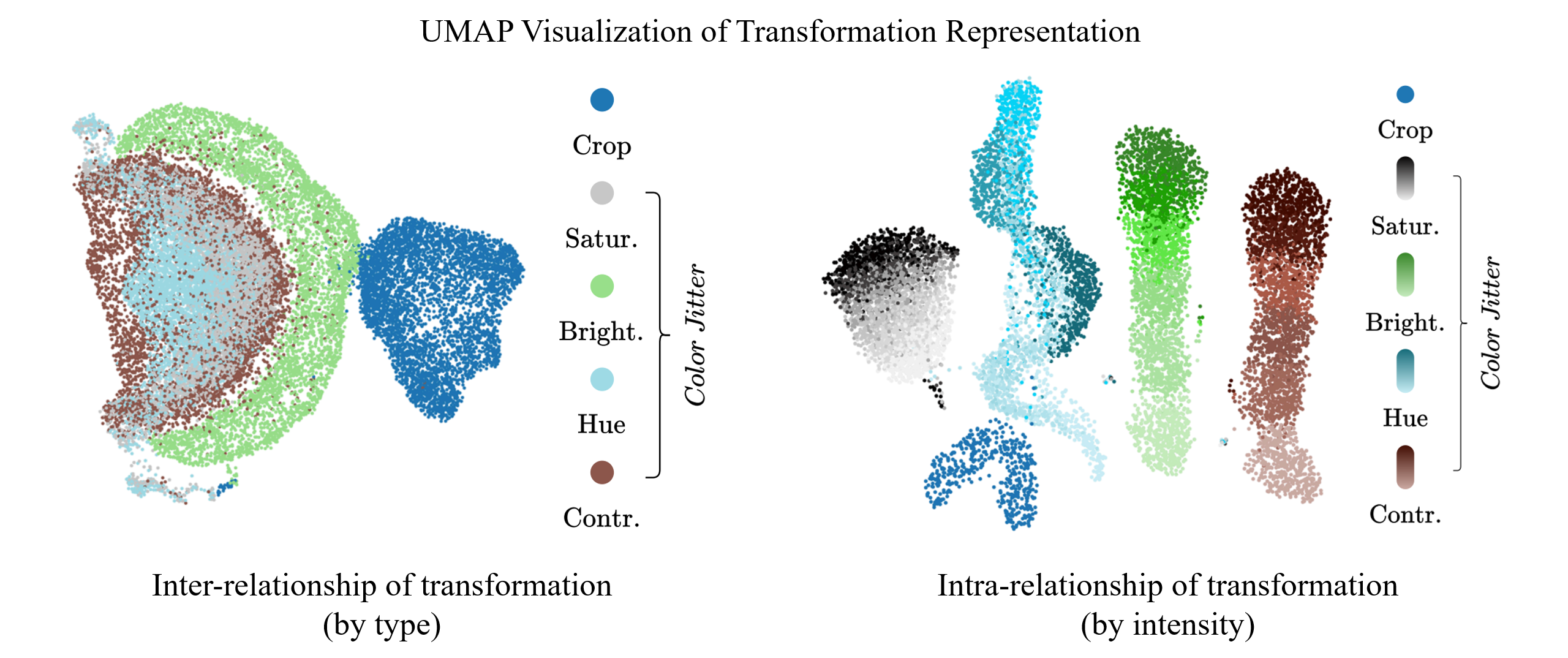
How the learned transformation representation reflects the actual transformation
STL effectively captures the underlying structure of transformations. UMAP visualizations show that STL learns meaningful transformation representations without explicit transformation labels.
- Inter-relationship of transformations: STL groups similar transformations together, capturing meaningful relationships.
- Intra-relationship of transformations: STL organizes transformation representations by intensity, showing smooth transition.
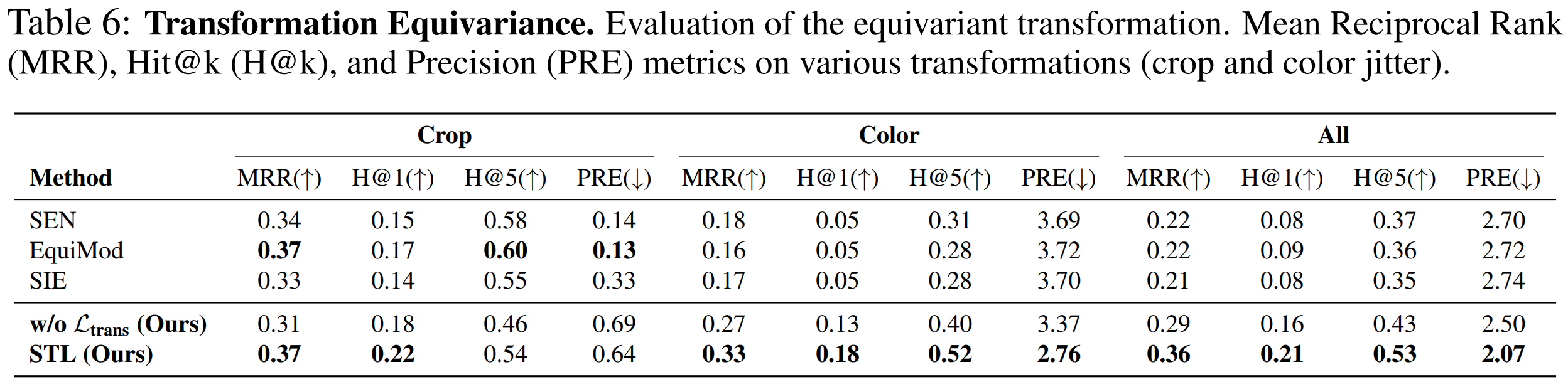
How the equivariant transformation reflects the actual transformation in the representation space
STL ensures that transformations in the representation space align with real-world transformations. Evaluation with Mean Reciprocal Rank (MRR), Hit@k, and Precision (PRE) confirms that STL learns precise equivariant transformations.
- STL achieves the highest MRR and H@1 scores, outperforming previous methods in transformation alignment.
- Effectively learns equivariant transformations without requiring explicit transformation labels.
Citation
@inproceedings{yu2024stl,
title={Self-supervised Transformation Learning for Equivariant Representations},
author={Jaemyung Yu and Jaehyun Choi and Dong-Jae Lee and HyeongGwon Hong and Junmo Kim},
year={2024},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
}